TL;DR
The existence of category selectivity does not imply that the form of selectivity is identical. Human category selectivity is highly consistent across individuals. ANN units diverge systematically from the human brain and do not converge across models.
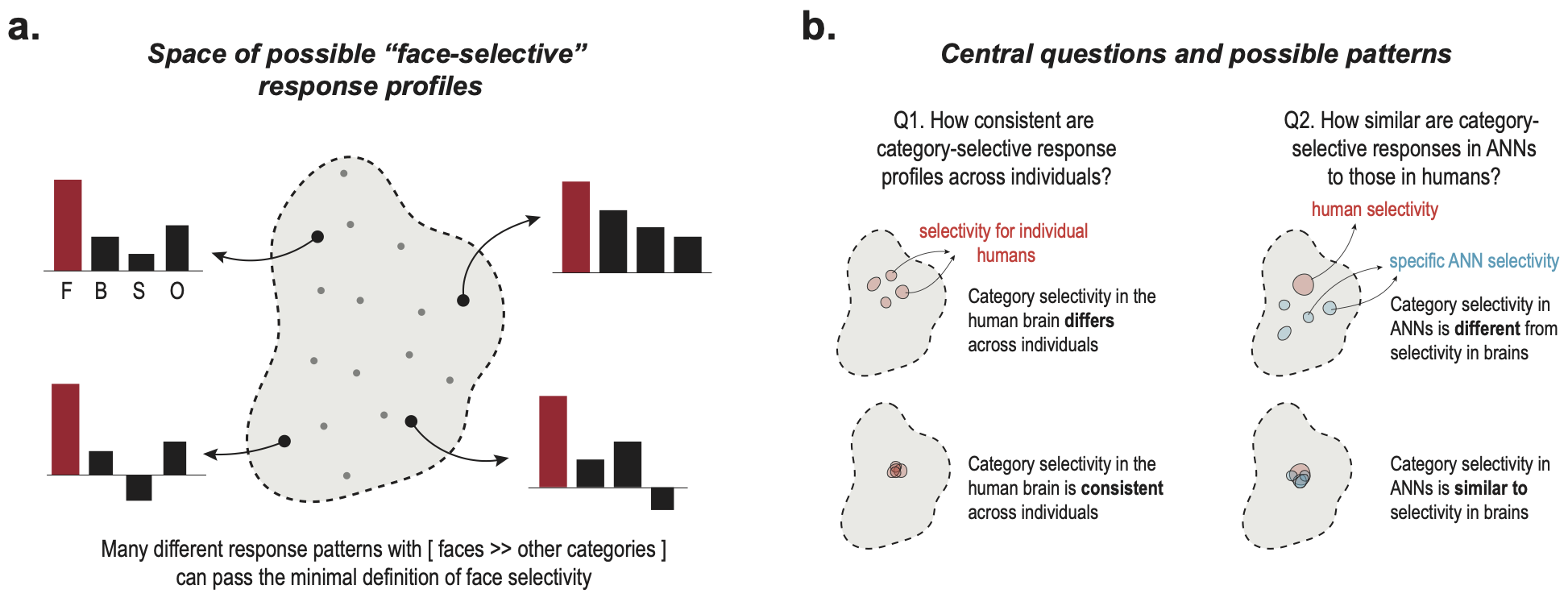
Central challenge: The minimal definition of category selectivity is underconstrained
A voxel or unit is deemed "face-selective" if it responds more to faces than to other
categories — but infinitely many response patterns satisfy this minimal criterion.
Without examining the full stimulus-level response profile, we cannot know whether
the form of ANN selectivity matches what is observed in the human brain.
·
Figure 1. Conceptual framework. (a) The response profile space: every point satisfies
the minimal selectivity criterion (preferred > other), but response profiles differ widely.
(b) The study compares category-selective response profiles in human category-selective regions
and ANN category-selective units.
Response profile explorer · schematic
Each point is a face-selective response profile (faces > other categories).
Click any point to reveal its full response pattern across categories.
← click a point
Human FFA
ANN unit (example)
Other face-selective profiles
Research questions
Q1: Do different brains exhibit the same form of category selectivity?
Yes! Category-selective regions are strikingly consistent — establishing a human-human ceiling for model comparison.
Q2: Do ANN units exhibit the same form of category selectivity as the brain?
No! ANN units fall well below the human-human ceiling in every model tested — regardless of the selectivity threshold, functional localizer, and category-selective fROI.
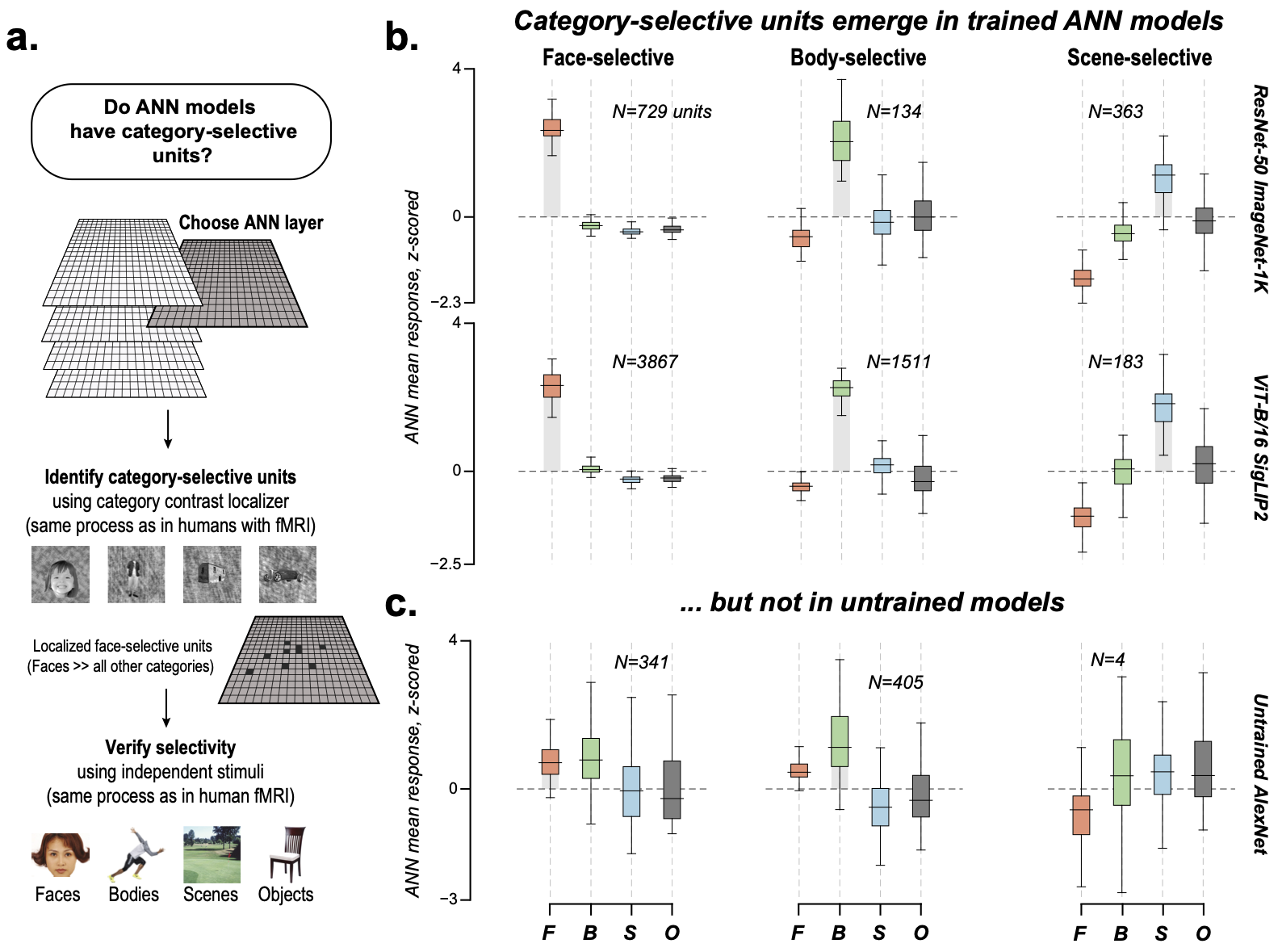
Finding 1: Category-selective units emerge only in trained, but not untrained, ANNs
Using the same localizer procedure applied in human fMRI, we identified category-selective
units across 55 ANN models (35 trained + 20 untrained). All pretrained models show robust face-, body-, and
scene-selective units that generalize to an independent stimulus set, but randomly initialized
models showed no reliable selectivity. Training is necessary for category selectivity
to emerge.
·
Figure 2. (a) Localization pipeline. (b) Trained models (ResNet-50, ViT-B/16)
show reliable face-, body-, and scene-selective units. (c) An untrained AlexNet instance
shows no generalizable selectivity.
Responses to independent stimuli (Prince et al., 2024)
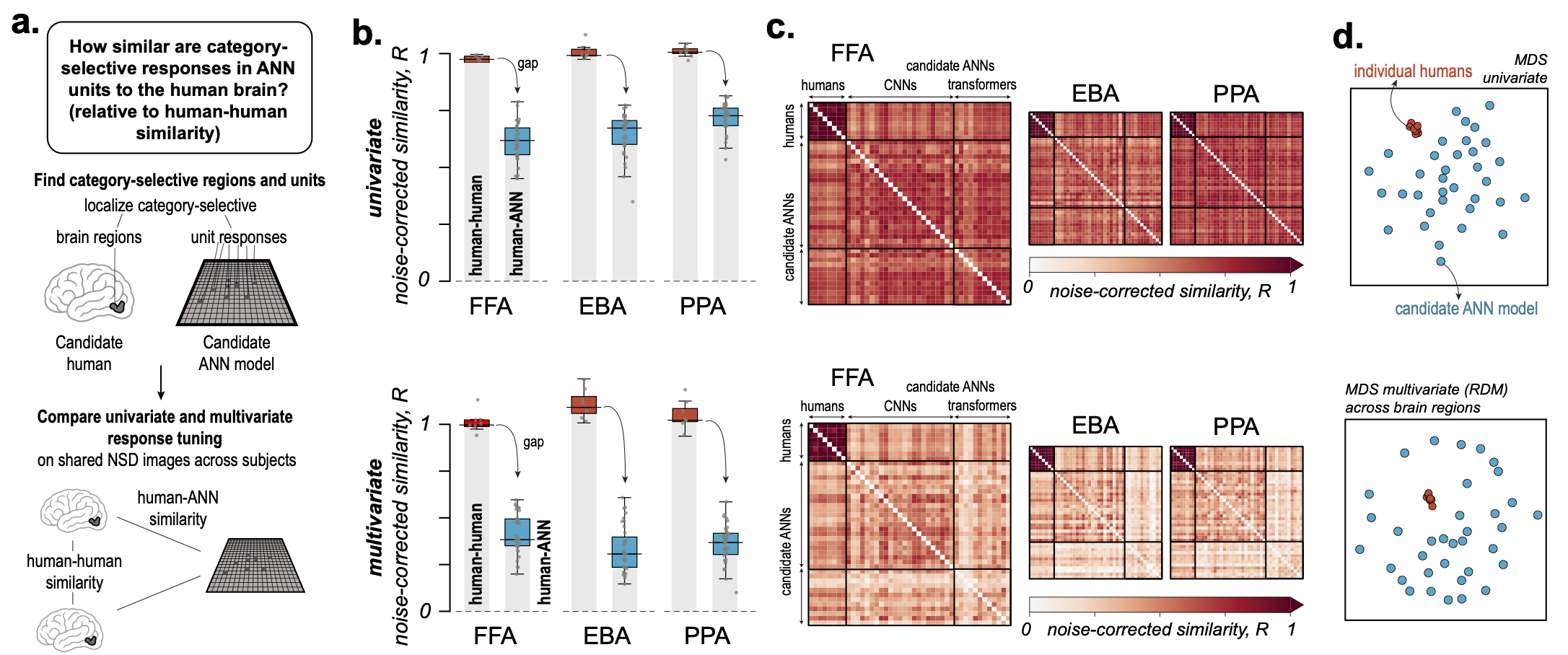
Finding 2: Human category-selective responses are strikingly consistent across individuals
· Finding 3: ANN units fall well below the human-human ceiling — in every model tested
Category-selective voxel responses in FFA, EBA, and PPA are strikingly consistent across all 8 subjects —
defining the human-human ceiling. Every ANN model tested falls substantially below this ceiling,
across both univariate and multivariate measures, and across all choices of selectivity thresholds,
functional localizers, and category-selective regions.
·
Figure 3. ANNs fall well below the human-human ceiling. (a) Schematic of the comparison. (b) Noise-corrected univariate
and multivariate correlations: human-human pairs are highly similar; human-ANN pairs are substantially
lower. (c) Pairwise correlations across all humans and models. (d) MDS visualization.
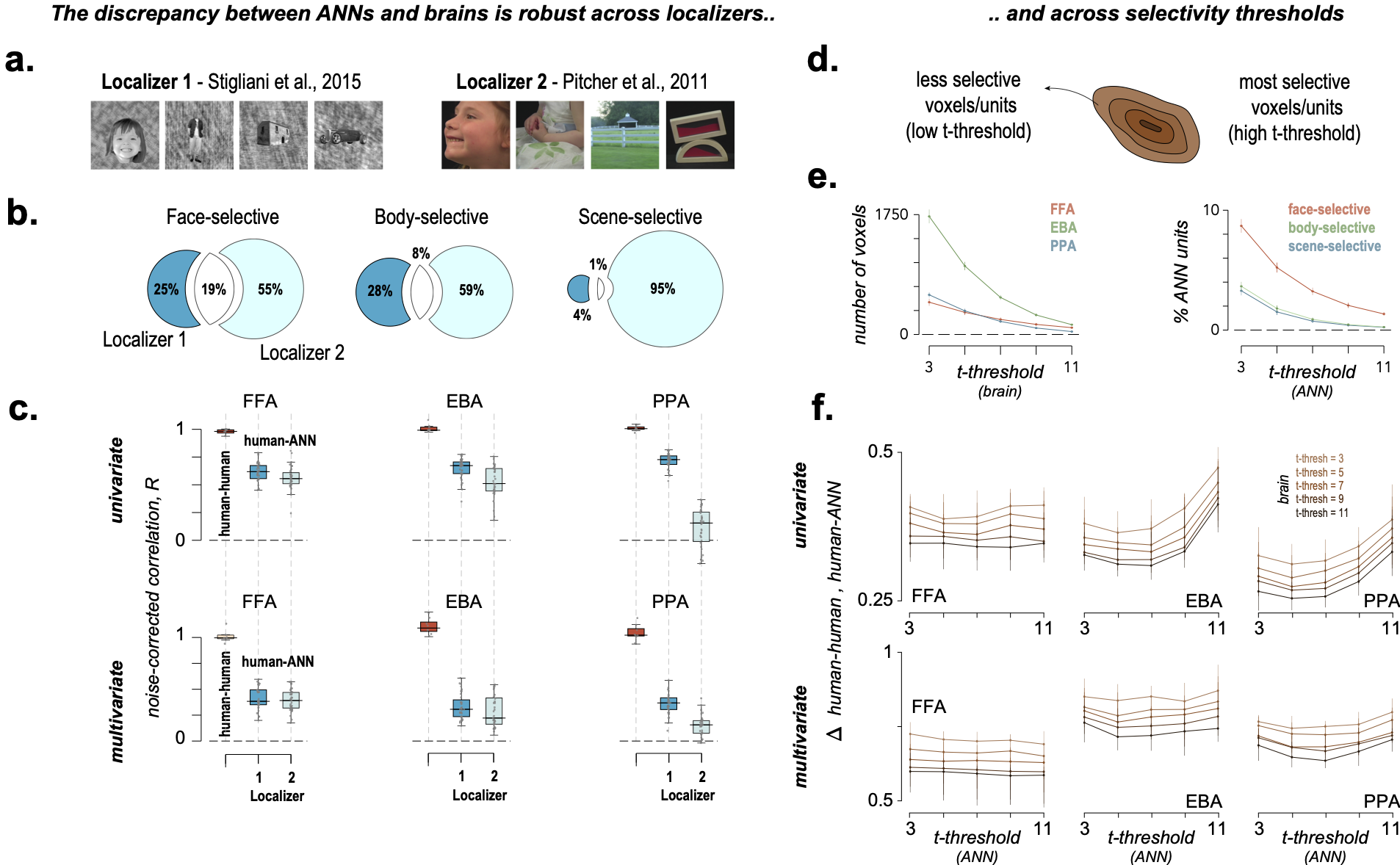
Figure 4. The ANN-brain discrepancy is robust across analysis choices.
(a) Two independent functional localizers. (b) Venn diagrams showing low overlap between
units identified by each localizer.
(c) Human-human similarity consistently exceeds human-ANN similarity across both localizers,
regions, and measures. (d-e) Higher t-thresholds identify progressively fewer but more
selective voxels/units. (f) The human-human minus human-ANN gap remains stable across
the full range of selectivity thresholds, for both univariate and multivariate comparisons.
Similarity boxplot
Hover a point to see system and correlation · click to pin highlight across both panels
Representational dissimilarity matrix (RDM)
Hover cells to see pair name and correlation value.
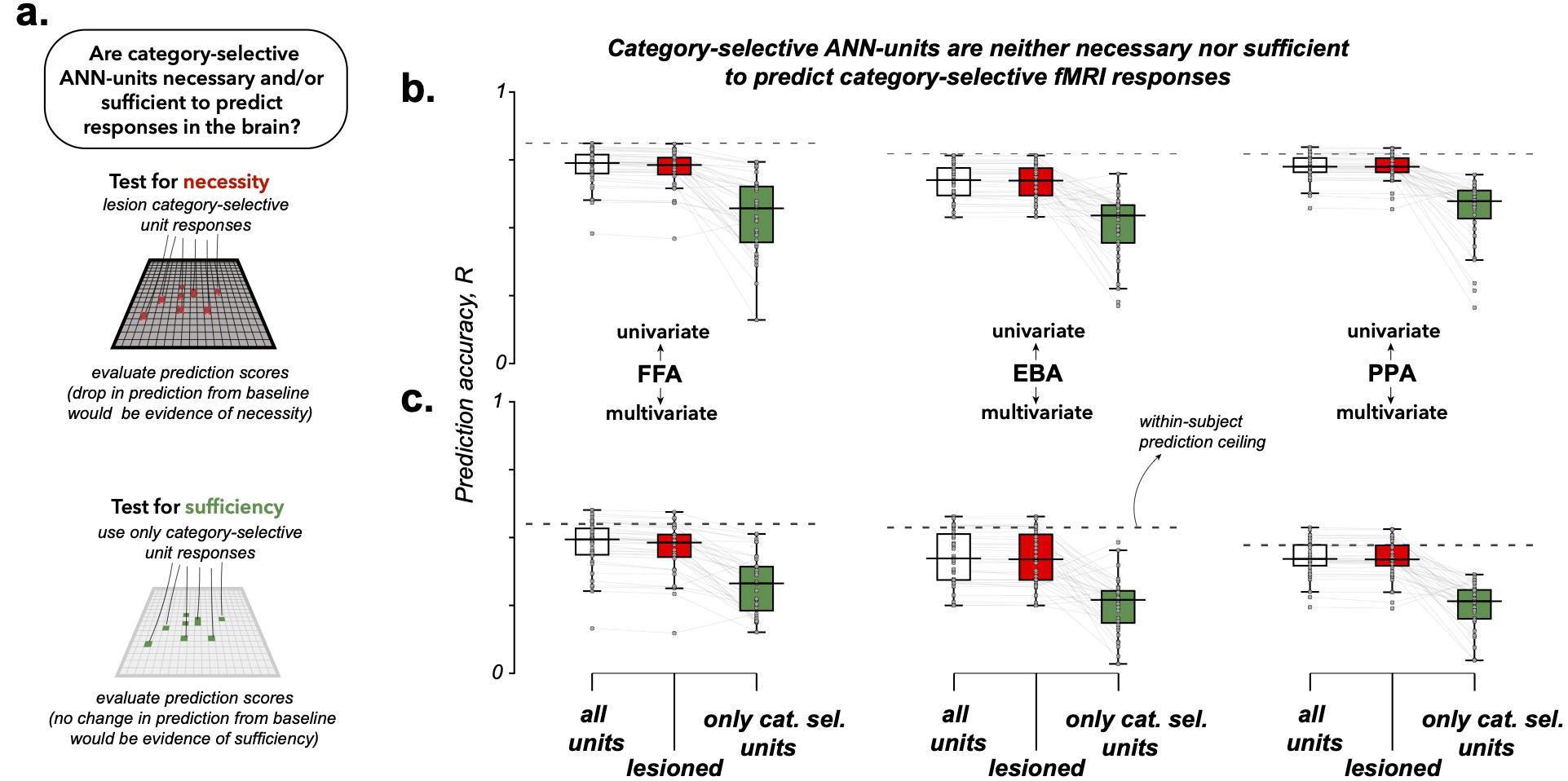
Finding 4: Category-selective ANN units are neither necessary nor sufficient for predicting brain responses
Voxel-wise encoding models trained on all units in a layer predict brain responses at
within-subject ceiling. Removing category-selective units causes no meaningful drop in
accuracy — but using only those units substantially reduces it. The information needed
to predict brain responses is distributed broadly across the layer, not concentrated in
the units a functional localizer deems category-selective.
·
Figure 5. Category-selective units do not drive brain response predictions (a) Schematic of the necessity and sufficiency tests.
(b-c) Univariate and multivariate prediction accuracy for encoding models trained on all units, lesioned category-selective units, and using only
category-selective units, for FFA, EBA, and PPA.
Encoding model explorer · hover a point to track it across conditions
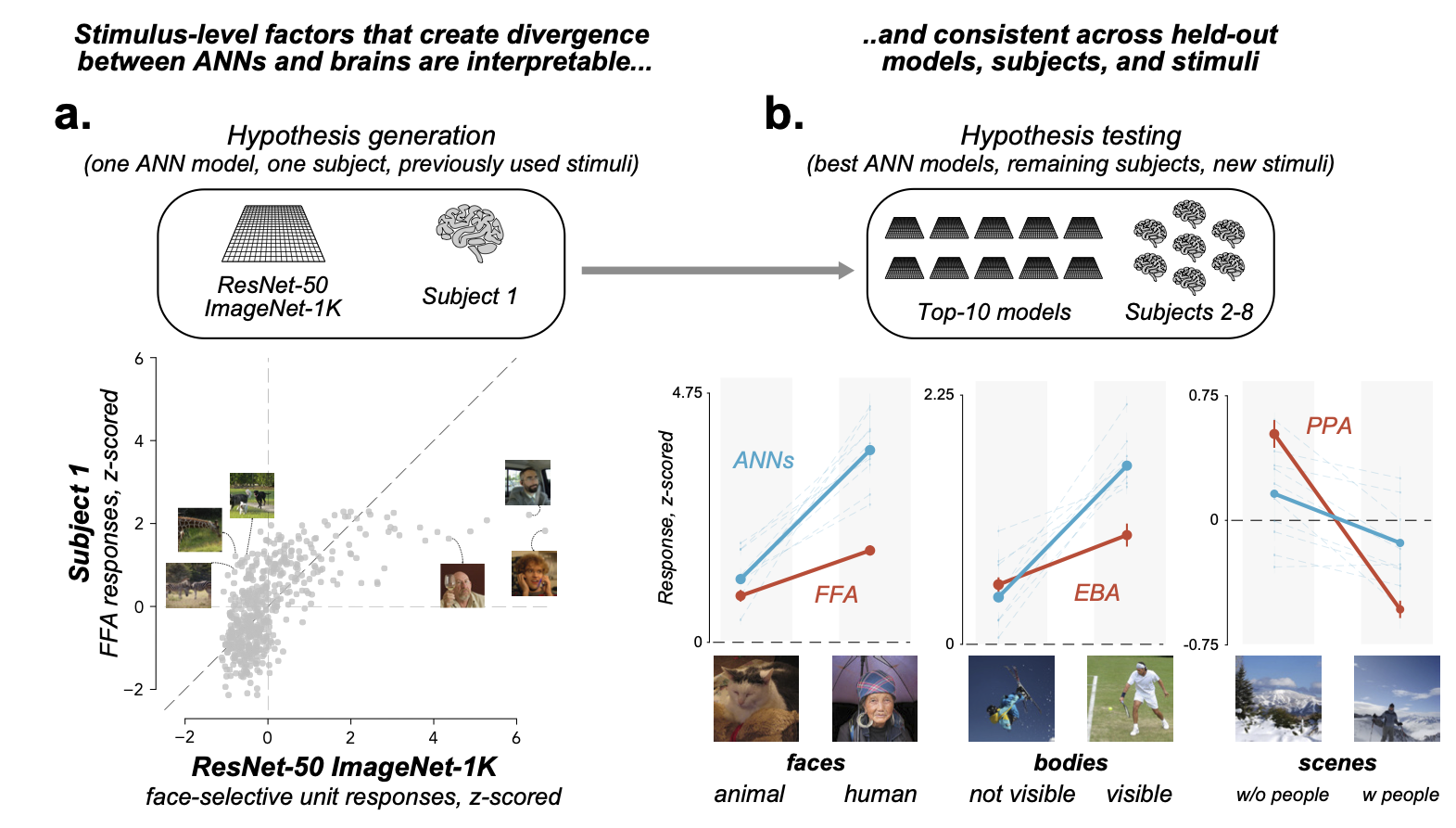
Finding 5: The differences between category selectivity in ANNs and brains are systematic and interpretable
The divergences between ANN unit responses and human category-selective regions are not
arbitrary — they reflect simple, interpretable stimulus-level features. These candidate
factors generalized to held-out subjects, models, and stimuli.
Face selectivity
FFA:Human faces≈Animal faces
ANNs:Human faces≫Animal faces
Body selectivity
EBA:Exposed limbs≈Covered bodies
ANNs:Exposed limbs≫Covered bodies
Scene selectivity
PPA:Scenes without people≫Scenes with people
ANNs:Scenes without people≈Scenes with people
·
Figure 6. Stimulus-driven divergences are systematic and interpretable (a) Hypothesis generation: scatter of ANN vs. brain z-scored
responses per image — outlier stimuli reveal interpretable groupings.
(b) Generalization to held-out models, subjects, and stimuli.
Stimulus divergence scatter · hover points to see images
Large ANN-brain discrepancy
Other stimuli
In the live site, hovering a point loads its NSD image from
images/nsd/{image_id}.jpg.
Current ANNs do not exhibit the form of category selectivity observed in the human brain
A category preference alone can arise from many different response patterns. The existence of category-selective units in ANNs does not imply that they exhibit the same form of category selectivity as the human brain.
Recommendations
Use the same localizer procedure as human neuroimaging and verify that selectivity generalizes to an independent stimulus set
Go beyond category preference — compare full stimulus-level response profiles across hundreds of natural images
Confirm that conclusions are stable across multiple localizer choices
ANN category-selective units differ from category-selective voxels in systematic and interpretable ways. Current ANN models do not yet share the biological invariances present in human category-selective cortex. Hence, ANN category-selective units cannot yet be equated with human category-selective voxels.
Recommendations
Use voxel-wise encoding models rather than direct unit comparisons; relevant features are distributed across the layer, not concentrated in selective units
Use our interpretable diagnostic tests (human vs. animal faces; visible vs. obscured limbs; scenes with vs. without people) as a useful starting point for evaluating brain-like selectivity
Open question 1
What developmental and evolutionary pressures give rise to the stable, invariant category representations observed in human visual cortex?
Open question 2
What determines the stability of category-selective representations? What model constraints are needed to achieve brain-like category selectivity?
Citation
Dipani, A., & Ratan Murty, N. A. (2026). Category selectivity observed in the human
brain is distinct from category selectivity observed in artificial neural networks.
bioRxiv.
https://doi.org/10.64898/2026.05.29.728609
Show BibTeX ↓
@article{dipani2026category,
title = {Category selectivity observed in the human brain is distinct
from category selectivity observed in artificial neural networks},
author = {Dipani, Alish and Ratan Murty, N Apurva},
journal = {bioRxiv},
pages = {2026--05},
year = {2026},
doi = {10.64898/2026.05.29.728609},
url = {https://doi.org/10.64898/2026.05.29.728609}
}